搜集子域名的两个技巧
在推上看到的,算一个可搜集的tips吧,原理是利用archive自己抓取的历史页面引用源,筛选去重即可
命令 :

tips 2
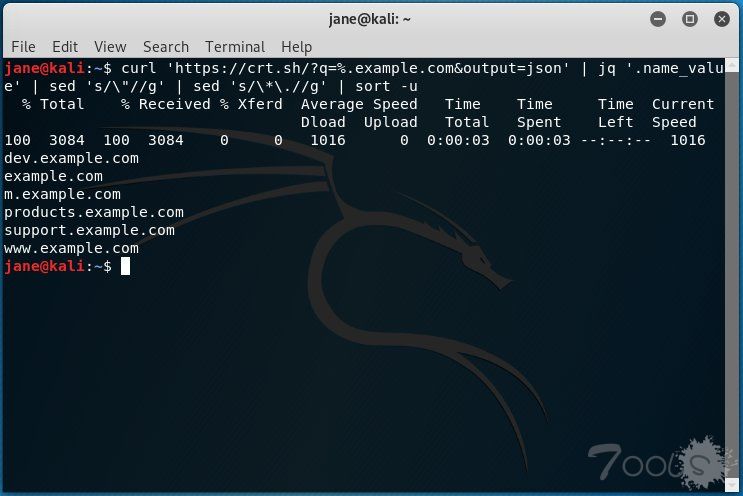
利用证书查询子域名,crt.sh这个工具可以按通配符域名查询所有证书的详情。
如果没有jq命令就这样
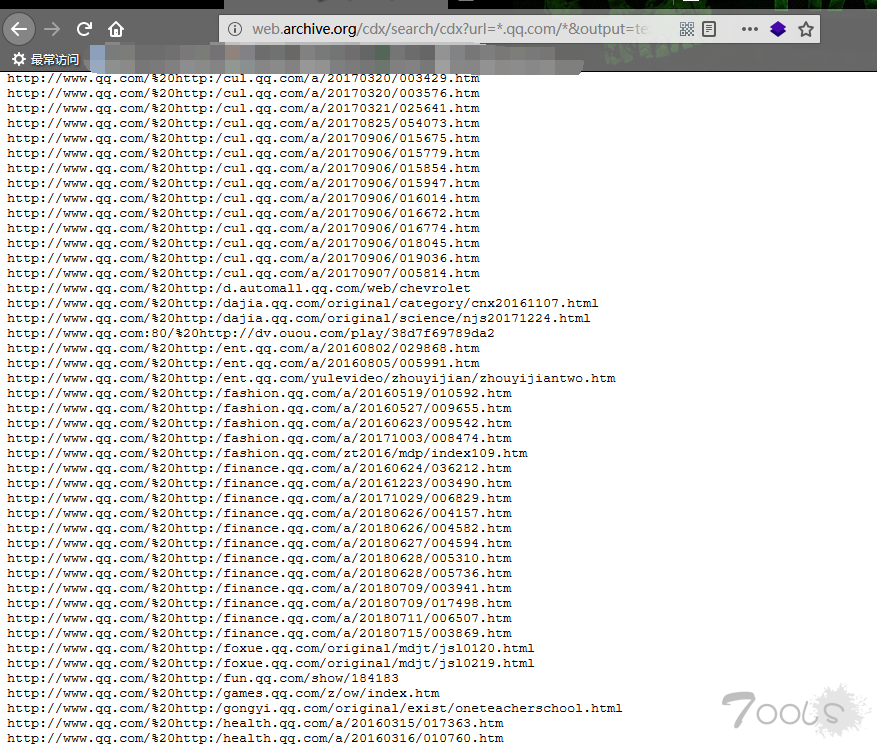
web.archive.org互联网档案馆(Internet Archive)是一家以普及利用所有知识为目标的非营利性数字图书馆。它提供永久存储和免费的公共访问的数字化材料信息集合,其中包括:网站、音乐、运动图像、以及近300万册公共领域书籍。它让公众上传和下载数字材料到其数据集群,但其大部分数据是靠其网络爬虫自动收集。它的Web归档文件系统Wayback机器包含了超过1500亿以上的网页存档。它还负责监督世界上最大的图书数字化项目。
命令 :
curl -s "http://web.archive.org/cdx/search/cdx?url=*.qq.com/*&output=text&fl=original&collapse=urlkey" |sort| sed -e 's_https*://__' -e "s/\/.*//" -e 's/:.*//' -e 's/^www\.//' | sort -utips 2
利用证书查询子域名,crt.sh这个工具可以按通配符域名查询所有证书的详情。
crt.sh is a web interface to a distributed database called the certificate transparency logs.
curl 'https://crt.sh/?q=%.example.com&output=json' | jq '.name_value' | sed 's/\"//g' | sed 's/\*\.//g' | sort -u如果没有jq命令就这样
curl -s "https://crt.sh/?q=%.example.com&output=json" | grep -Po '"name_value":.*?[^\\]",' | cut -d\" -f4 | sed 's/\*\.//g' | sort -u
评论11次
第二个用的多
https://otx.alienvault.com/也能获取类似第一个那种
有点子高深
https://zhuanlan.zhihu.com/p/60031968?utm_id=0
感觉很厉害的样子,先操练一下看看准不准!
楼主测试过吗?准确率高不高?
就只会谷歌百度的site这个知识点学xi了
类似快照功能吧,第二个还可以
这就跟百度谷歌快照一样的吧
第二个用的多
有点高深啊 这个
是不是就像百度谷歌一样site这样的语法去抓取网页历史快照等信息这些呀 小白没整明白