如何科学的抢红包第二弹
0×00 背景
今天拜读了来自IDF实验室的《如何科学的抢红包:年末致富有新招,写个程序抢红包》,自己这段时间正在学习爬虫的相关知识,对scrapy框架有所了解,就在此代码基础上加进了scrapy,利用scrapy对文章中的“0×04 爬取红包列表”进行了重写。
0×01 scrapy框架
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。它也提供了多种类型爬虫的基类,如BaseSpider、sitemap爬虫等,最新版本又提供了web2.0爬虫的支持。
Scrach,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小刮刮吧。
简单的一句话:利用scrapy可以很简单的写出爬虫。
0×02 微博登入、红包可用性检查、指定红包抓取模块
这几个模板我单独放在一个weibo类中,方面后面的scrapy的调用分析
微博登入这块,可以参照http://www.tuicool.com/articles/ziyQFrb 这篇文章,里面很详细的记录了微博登入的全过程
代码copy大牛,并在此基础上进行了简单的修改:使用requests库进行页面的请求。
#-------------------------------------------------------------------------------
# Name: weibo
# Purpose:
#
# Author: adrain
#
# Created: 14/02/2015
# Copyright: (c) adrain 2015
# Licence: <your licence>
#-------------------------------------------------------------------------------
#!/usr/bin/env python
import sys
import requests
import re
import base64
import urllib
import rsa
import binascii
import os
import json
class weibo():
def __init__(self):
reload(sys)
sys.setdefaultencoding('utf-8&')
def weibo_login(self,nick,pwd):
print u'---weibo login----'
pre_login_url='http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=%s&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.15)&_=1400822309846' % nick
pre_logn_data=requests.get(pre_login_url).text;
#print pre_logn_data
servertime=re.findall('"servertime":(.*?),',pre_logn_data)[0]
pubkey = re.findall('"pubkey":"(.*?)",' , pre_logn_data)[0]
rsakv = re.findall('"rsakv":"(.*?)",' , pre_logn_data)[0]
nonce = re.findall('"nonce":"(.*?)",' , pre_logn_data)[0]
login_url='http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.15)'
su=base64.b64encode(urllib.quote(self.nick))
rsaPublickey= int(pubkey,16)
key = rsa.PublicKey(rsaPublickey,65537)
message = str(servertime) +'\t' + str(nonce) + '\n' + str(self.pwd)
sp = binascii.b2a_hex(rsa.encrypt(message,key))
post_data={
'entry': 'weibo',
'gateway': '1',
'from': '',
'savestate': '7',
'userticket': '1',
'pagereferer':'',
'vsnf': '1',
'su': su,
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'encoding': 'UTF-8',
'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype': 'META',
'ssosimplelogin': '1',
'vsnval': '',
'service': 'miniblog',
}
header = {'User-Agent' : 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)'}
login_data=requests.post(login_url,data=post_data,headers=header).text.decode("utf-8").encode("gbk",'ignore')
try:
suss_url=re.findall("location.replace\(\'(.*?)\'\);" , login_data)[0]
login_cookie=requests.get(suss_url).cookies
return login_cookie
print '----login success---'
except Exception,e:
print '----login error----'
exit(0)
def log(self,type,text):
fp = open(type+'.txt','a')
fp.write(text)
fp.write('\r\n')
fp.close()
def check(self,id):
infoUrl='http://huodong.weibo.com/hongbao/'+str(id)
html=requests.get(infoUrl).text
if 'action-type="lottery"' in html or True: #存在抢红包按钮
logUrl="http://huodong.weibo.com/aj_hongbao/detailmore?page=1&type=2&_t=0&__rnd=1423744829265&uid="+str(id)
param={}
header= {
'Cache-Control':'no-cache',
'Content-Type':'application/x-www-form-urlencoded',
'Pragma':'no-cache',
'Referer':'http://huodong.weibo.com/hongbao/detail?uid='+str(id),
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 BIDUBrowser/6.x Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
res=requests.post(logUrl,data=param,headers=header)
pMoney=re.compile(r'<span class="money">(\d+?.+?)\xd4\xaa</span>',re.DOTALL) #h获取所有list_info的正则
luckyLog=pMoney.findall(html,re.DOTALL)
if len(luckyLog)==0:
maxMoney=0
else:
maxMoney=float(luckyLog[0])
if maxMoney<10: #记录中最大红包小于设定值
print u'-----红包金额太少,不需要抽取-----'
return False
else:
print u"---------手慢一步---------"
print "----------......----------"
return False
return True
def getLucky(self,id):
print u'-----抽取红包中:'+str(id)+"-----"
if self.check(id)==False:
return
luck_url='http://huodong.weibo.com/aj_hongbao/getlucky'
lucky_data={'ouid':id,
'share':0,
'_t':0}
header= {
'Cache-Control':'no-cache',
'Content-Type':'application/x-www-form-urlencoded',
'Origin':'http://huodong.weibo.com',
'Pragma':'no-cache',
'Referer':'http://huodong.weibo.com/hongbao/'+str(id),
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/33.0.1750.146 BIDUBrowser/6.x Safari/537.36',
'X-Requested-With':'XMLHttpRequest'
}
cookie=self.weibo_login('xxxx','xxxx')
res=requests.post(luck_url,data=lucky_data,cookies=cookie).text
#print res
res_json=json.loads(res)
print res_json
if res_json["code"]=='901114': #今天红包已经抢完
print u"---------已达上限---------"
print "----------......----------"
self.log('lucky',str(id)+'---'+str(res_json["code"])+'---'+res_json["data"]["title"])
exit(0)
elif res_json["code"]=='100000':#成功
print u"---------恭喜发财---------"
print "----------......----------"
self.log('success',str(id)+'---'+res)
exit(0)
if res_json["data"] and res_json["data"]["title"]:
print res_json["data"]["title"]
print "----------......----------"
self.log('lucky',str(id)+'---'+str(res_json["code"])+'---'+res_json["data"]["title"])
else:
print u"---------请求错误---------"
print "----------......----------"
self.log('lucky',str(id)+'---'+res) 写完后,可简单使用一个id进行测试:
wb=weibo()
wb.getLucky(11111111) 首先是使用scrapy创建一个新的工程:
scrapy startproject weibo_spider 
由于是刚开始了解scrapy,简单是只是用到了items.py pipelines.py。
items.py说白了就是定义你要抓取那些东西。
比如我们这个就是抓取发红包的url及分析用到的id值,那么该写items文件内容:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class WeiboSpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url=scrapy.Field()
hongbao_id=scrapy.Field()
pass
后面就是主要爬虫程序的编写,该核心程序放在spiders文件夹下面,运行的时候会运行spiders目录下面的所有py文件
首先把代码贴出来,再慢慢说:
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.selector import Selector
from weibo_hongbao.items import WeiboHongbaoItem
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
import re
class weibo_spider(CrawlSpider):
name='weibo_spider'
allowed_domains=['weibo.com']
start_urls=['http://huodong.weibo.com/hongbao/']
rules=(
Rule(SgmlLinkExtractor(allow = (r'http://huodong.weibo.com/hongbao/special_.+?'))),
Rule(SgmlLinkExtractor(allow = (r'http://huodong.weibo.com/hongbao/top_.+?'))),
Rule(SgmlLinkExtractor(allow = (r'http://huodong.weibo.com/hongbao/cate?type=.+?'))),
Rule(SgmlLinkExtractor(allow = (r'http://huodong.weibo.com/hongbao/theme'))),
Rule(SgmlLinkExtractor(allow=(r'http://huodong.weibo.com/hongbao/\d+?')), callback="parse_page",follow=True),
)
def parse_page(self,response):
#ids=[]
sel=Selector(response)
item=WeiboHongbaoItem()
try:
id=re.findall('hongbao/(\d+)',response.url)[0]
item['hongbao_id']=id
item['url']=response.url
except Exception,e:
print 'the id is wrong!!'
return item allowed_domains 允许爬虫爬的domian域
start_urls 爬虫开始的url地址,这里就设置为让红包飞的主页
rules 是设定爬取的url的,allow是允许爬虫的url类型,还有一些拒绝爬行的可参考官方文档。这里前几个allow 用正则匹配处存在发红包的主题列表和排行榜列表,也就是把大神文章中的themeUrl和topUrl放在这里,这里面其实有个默认的参数是follow,默认是开启的,也就是会跟进到这个url页面里面继续爬行。最后一个是要分析的,红包地址都是http://huodong.weibo.com/hongbao/ 数字id,这个后面加了个callback,也就是说爬行这个url返回的数据放进callback函数中进行处理
parse_page函数中的参数response,该参数的属性参考官方文档,很简单。 由于我们只是需要id值放在weibo.getLucky中,直接用到了正则去response.url中进行匹配,直接返回item
到此直接可以抓取到发红包的url,红包的id值,但是直接运行是没有结果的,我们需要用到管道文件pipelines.py把结果展示出来
编写pipelines.py:
from scrapy import signals
import json
import codecs
from weibo_hongbao.weibo import weibo
class WeiboHongbaoPipeline(object):
def __init__(self):
self.file=codecs.open('weibo.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
wb=weibo()
wb.getLucky(item['hongbao_id'])
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self,spider):
self.file.close() 最后把所有找到的红包url及id放进了文件中
结果:
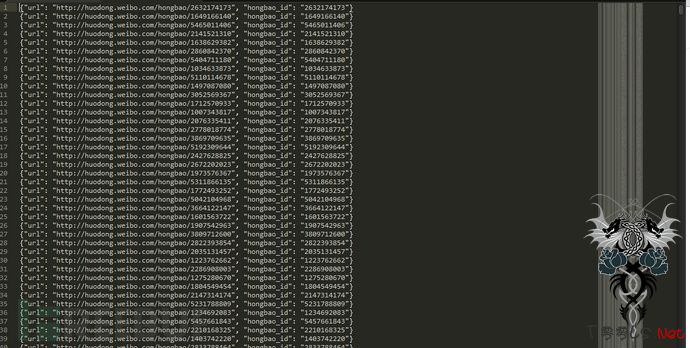
抓取到的还是相当多的。
程序运行:
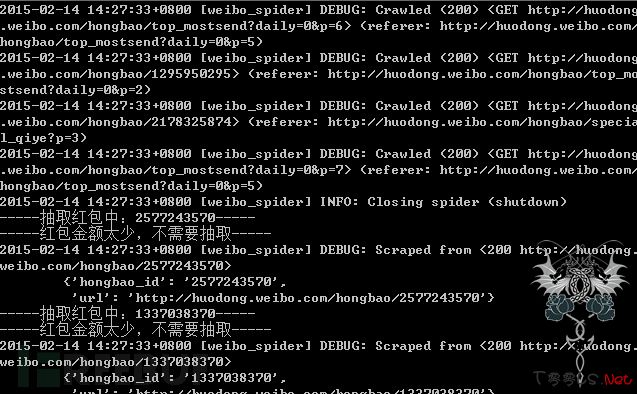
评论20次
首选得到土豪维信群
玩得太骚了~~~
我晕,乖孩子。我说我怎么抢不到。。。
原不怪我总没抢到红包,原来大神都已经开发全自动了
程序PK手工的杰作
lz抢了几块钱:???
已经公开的都是玩烂的了
技术宅 就是不一样。。抢红包都是高科技
技术抽红包。。
好牛,一个都抢不到呢
抢得支付宝的红包,一毛钱都没抽到过。
难怪我抢不到
现在都流行批量和全自动了。。。
怪不得别人都抢不到
这不是freebuf上的文章吗
@风之传说 我擦 你怎么复活了啊
抢红包都搞到这么牛逼了啊
你要是能截个图,截个日赚百元神马的,我觉得下载量绝对空前绝后。。
原不怪我总没抢到红包,原来大神都已经开发全自动了
第二张图被水印挡住了。。。。