关于Burp Intruder模块的小技巧
0x01:
也算不上什么高大上的技巧,只是之前自己在渗透测试过程中学习到的,分享出来,希望对像我这样的新手有所帮助~
在一些渗透测试的教程中,用Intruder模块爆破或fuzz的时候,他们只讲到了通过返回包的长度或者状态码来识别是否爆破成功。
其实已经有前辈写的很好了,链接:https://t0data.gitbooks.io/burpsuite/content/chapter8.html
0x02:
在一些渗透测试的教程中,用Intruder模块爆破或fuzz的时候,他们只讲到了通过返回包的长度或者状态码来识别是否爆破成功/是否fuzz出我们想要的内容。
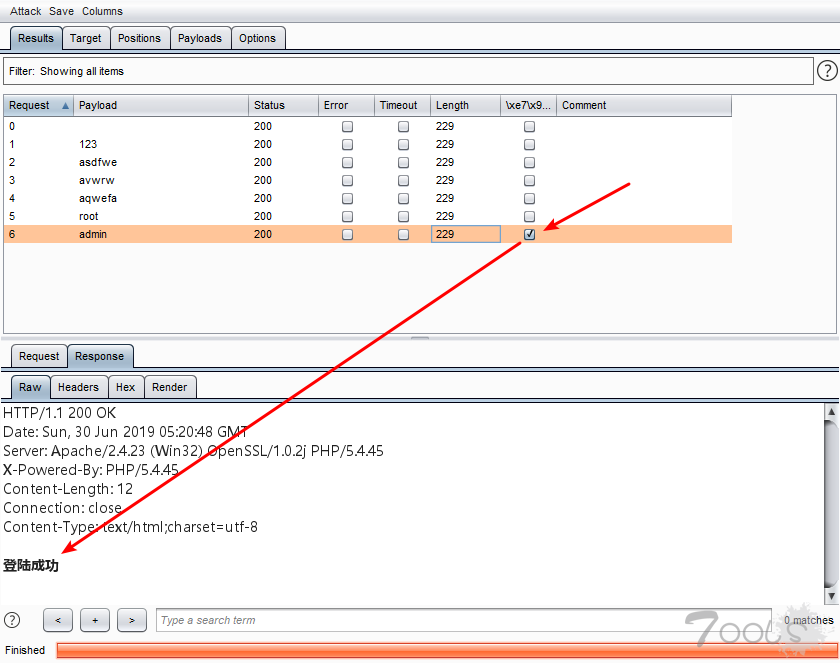
其实在Intruder->Option->Grep-Match中提供了返回包匹配内容的功能,可以通过简单的字符串或正则表达式进行内容匹配。
0x03:
图解:
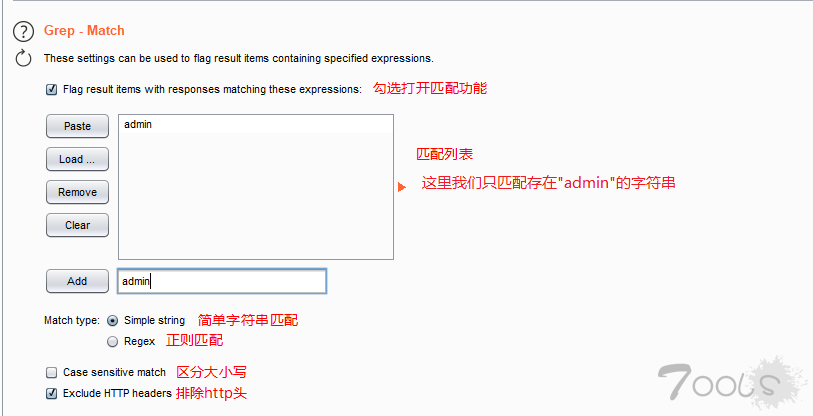
匹配内容后,效果如下:
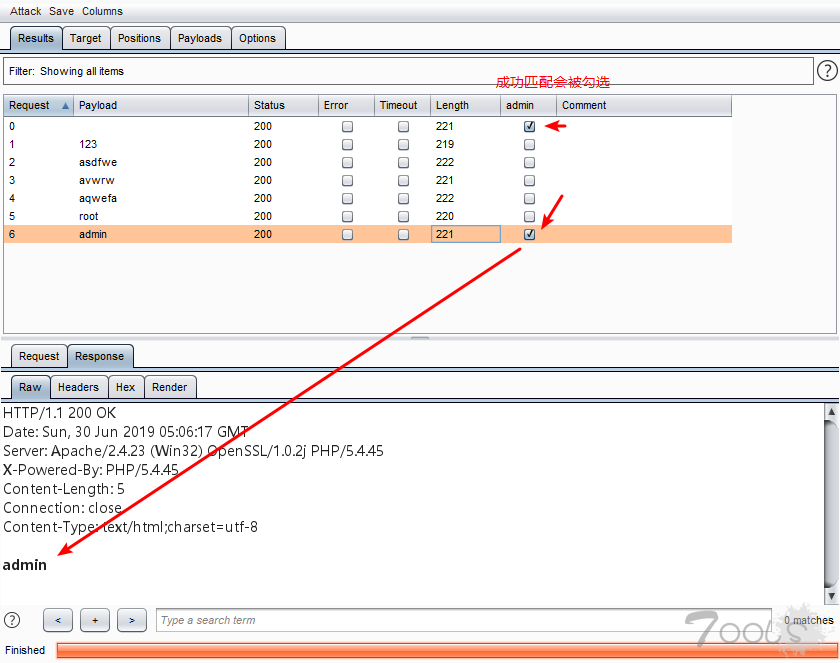
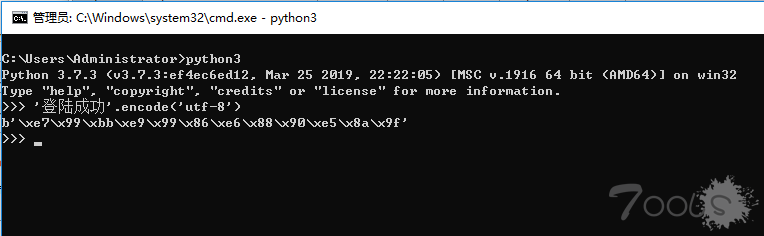
在一些情况下需要匹配中文,可以使用正则表达式匹配十六进制,操作如下: 先用python把中文转成十六进制(不局限于此方法)
然后设置正则匹配模式,把十六进制添加进去
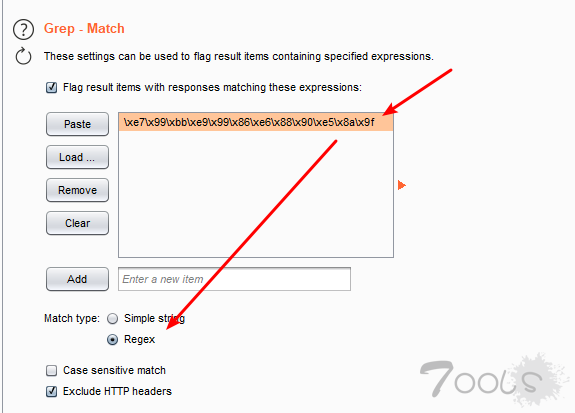
结果:
0x04:
如果存在不对的地方,希望前辈指出,我及时更正,避免误导他人~.gif) 有其他技巧也希望前辈能分享一些。
有其他技巧也希望前辈能分享一些。
也算不上什么高大上的技巧,只是之前自己在渗透测试过程中学习到的,分享出来,希望对像我这样的新手有所帮助~
在一些渗透测试的教程中,用Intruder模块爆破或fuzz的时候,他们只讲到了通过返回包的长度或者状态码来识别是否爆破成功。
其实已经有前辈写的很好了,链接:https://t0data.gitbooks.io/burpsuite/content/chapter8.html
0x02:
在一些渗透测试的教程中,用Intruder模块爆破或fuzz的时候,他们只讲到了通过返回包的长度或者状态码来识别是否爆破成功/是否fuzz出我们想要的内容。
其实在Intruder->Option->Grep-Match中提供了返回包匹配内容的功能,可以通过简单的字符串或正则表达式进行内容匹配。
0x03:
图解:
匹配内容后,效果如下:
在一些情况下需要匹配中文,可以使用正则表达式匹配十六进制,操作如下: 先用python把中文转成十六进制(不局限于此方法)
然后设置正则匹配模式,把十六进制添加进去
结果:
0x04:
如果存在不对的地方,希望前辈指出,我及时更正,避免误导他人~
有其他技巧也希望前辈能分享一些。
评论62次
匹配早就知道,但是匹配中文一直让我费解,这次知道了
学些了 感谢分享
匹配成功! 思路言简意赅,大赞
回显看不到中文怎么破,楼主是用插件显示中文的么?
在burp->UserOption->display里面可以修改编码,这个百度应该也有教学的
这个功能很实用,期待楼主发写更多实用的方法
中文的精准定位,还是可以的,我一般也是找成功页面的特定字符
下面不是有个功能可以直接从响应包中抓取匹配内容嘛
从没注意过又匹配功能,很实用,感谢分享
哈哈,很早就知道了,还可以通过正则匹配出返回包里面的一些内容,达到简单爬虫效果。。。
回显看不到中文怎么破,楼主是用插件显示中文的么?
匹配中文转换的16进制,学到了,感谢分享,又多了一种过滤方式
16进制可以匹配正则 厉害
直接百度UrlEncode编码/解码就可以了啊,没必要这么麻烦
之前一直看长度,学xi了
匹配中文的姿势学到了 已加入笔记本
在遇到返回长度相同的情况的确需要匹配内容,中文匹配16进制学到了。
这个姿势够骚。学xi了。
有没有可以不通过十六进制的方式来匹配中文的?我记得在某个地方可以直接输入需要匹配的中文关键字就可以匹配中文了。
这个我还真不知道欸。。
感谢分享,这姿势以前还真没用过,一直用长度辨别匹配。
有没有可以不通过十六进制的方式来匹配中文的?我记得在某个地方可以直接输入需要匹配的中文关键字就可以匹配中文了。
我一般都会加上关键字匹配 有些返回包的数据格式固定,长度和返回状态都无差别,这样对我们的fuzz结果会有影响,加上这些关键字匹配对结果更容易判断一点