GyoiThon源码分析:基于机器学习的自动化渗透测试工具
浏览此文之前,建议先阅读GyoiThon的README.md,并简单使用此工具
老早前就想过在自己写的工具里加入Ai算法,可是却一直因为别的学习目标优先级比较高,所以总是没分配到时间去学习Ai基础算法这方面的知识。刚好前段时间实验室的领导让我学习一下机器学习的算法,打算应用到公司的安全产品里,我就专门去了解了多个这方面的工具,学到了很多思路。
我们就先来看一下 Gyoithon 这款结合了Ai算法的工具的源码,从源码中学思路。
话不多说,直接读代码。
目录里相关的文件与作用,train_data:用来训练的数据源、trained_data:训练后的数据。config.ini:配置文件、host.txt:目标信息、gyoithon.py:启动程序、GyoiClassifier.py:机器学习算法的分类程序、GyoiExploit.py:调用metasploit、GyoiReport.py:生成报告、img:存图片、report:报告模板的前端样式。
在gyoithon.py文件里,找到main函数,main在程序里一般代表的是程序入口,意味着gyoithon.py是程序的启动类。
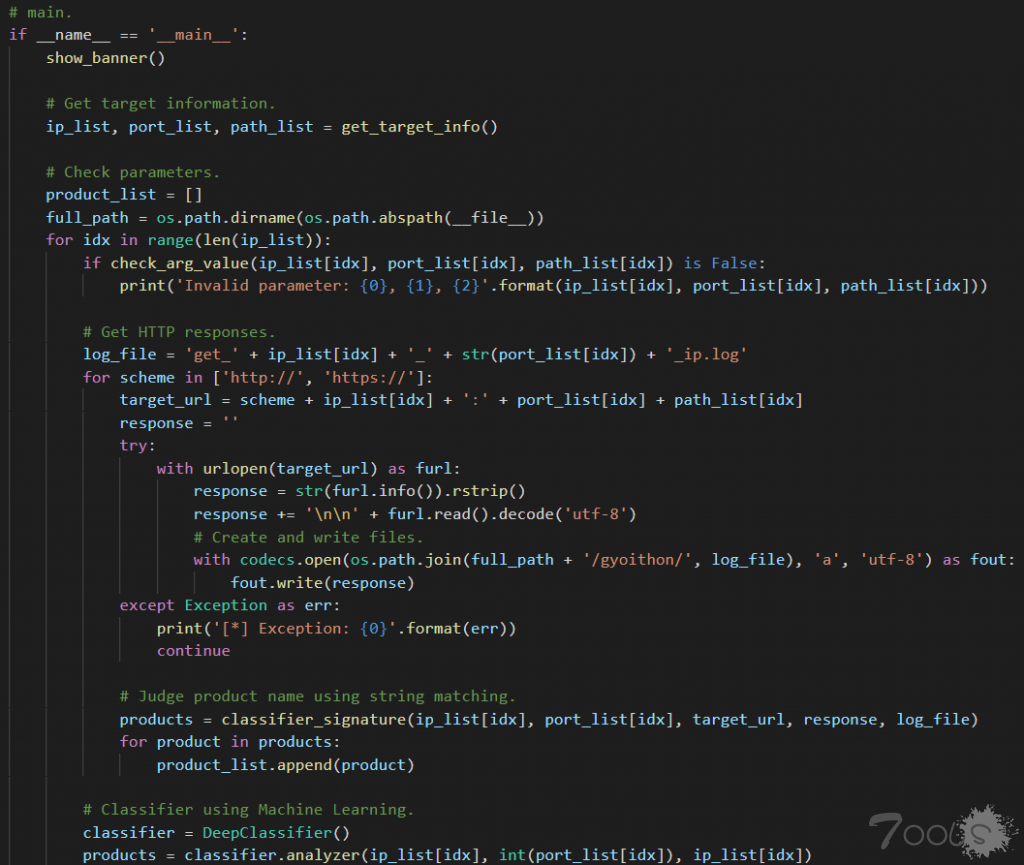
所以我们先看gyoithon.py。第一个调用的函数是show_banner(),输出字符,给用户做一个展示。一般的工具包括我自己写的工具,也会在启动时去简单的输出一些如版本、名字、作者等工具相关的信息。大家日常使用其他工具时,应该也经常看到。当然不是必须的,看个人喜好。
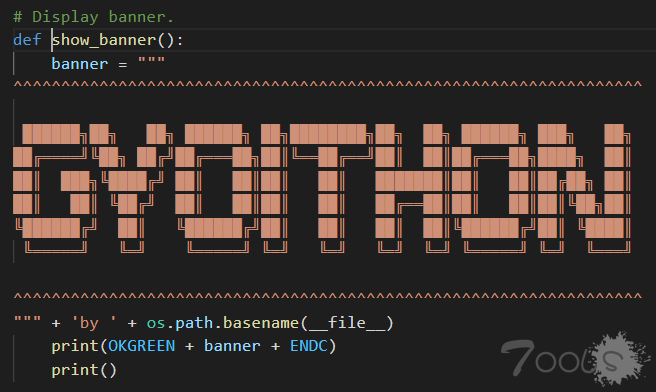
接下来,首先获取目标信息。

跟进get_target_info()里,它先获取了文件路径、然后循环获取 host.txt 文本里的内容,这里主要就是为了拿到 host.txt 里的内容,有使用GyoiThon的朋友都知道 host.txt 里的存的就是目标的信息。
之后将获取到的目标信息分别存入ip、port、path变量里return给调用者。
host.txt文本里的内容:ip地址、端口、目标网站路径。
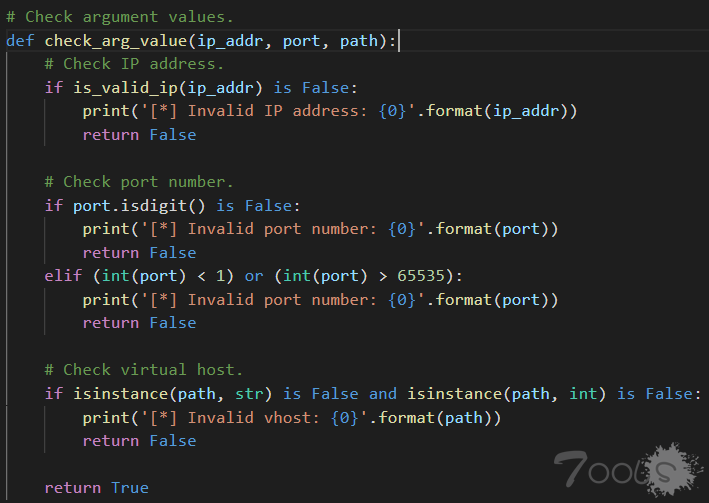
回到mian,接下来调用 check_arg_value()检查用户输入的目标参数。

跟进 check_arg_value()分别对三个参数进行了检查;判断ip地址是否合法、判断port是否由数字组成,且不能小于1和大于65535、判断path是否是字符串,和数字类型。
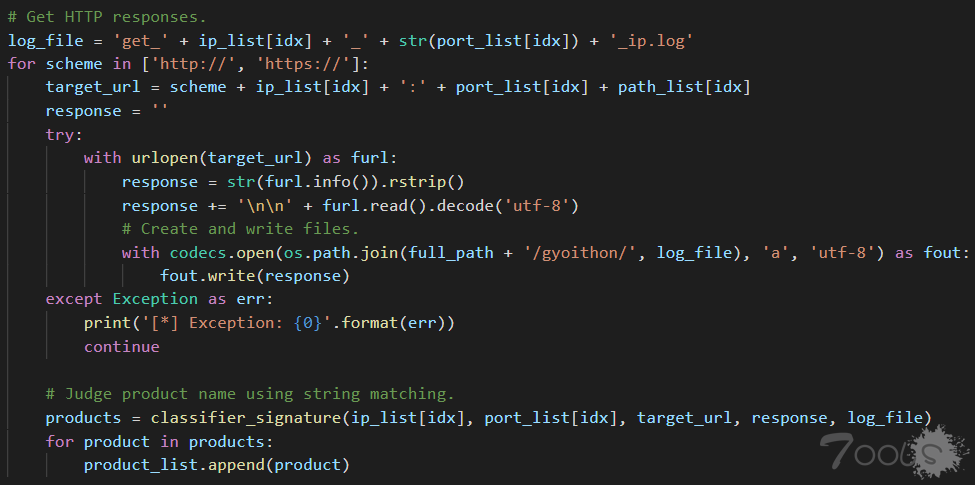
回到mian,目标校验通过后,先做两个字符串拼接,分别是拼接扫描日志.log、和给在host.txt文件里的目标参数加上http://、https://。
往下, urlopen(target_url) 向目标发起请求拿到responses后,将responses的内容在刚才拼接的路径下创建并写入.log文件,写入的.log文件不出意外,会保存在/GyoiThon/gyoithon/下。
再往下,跟大多数指纹识别工具一样,这里也是有用到字符串匹配来判断产品名称的方法。
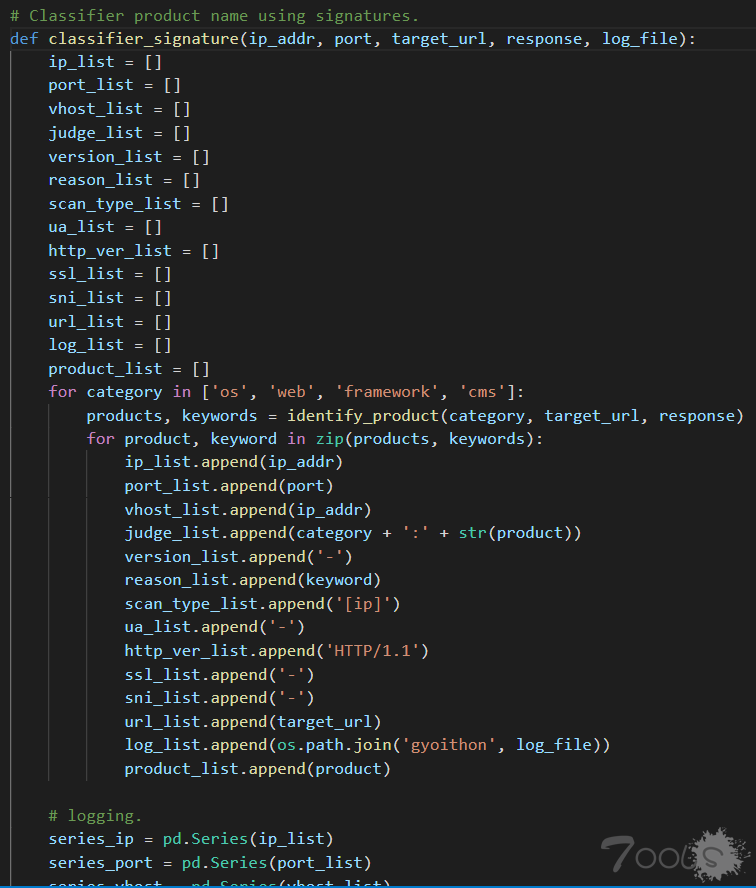
跟进 classifier_signature( ) ,可以看到首先是给定了四种类型,分别是 'os'、'web'、 'framework'、 'cms',再调用 identify_product( ) 去执行真正的匹配操作,返回结果后,将拿到的 products, keywords 存到日志里,最终将products 追加进 products_list 后,return给调用者。
这里记一下 图二 倒数第二行的:
df.sort_values(by='port', ascending=False).to_csv(os.path.join(saved_path, 'webconf.csv')) ,这里是将此次响应的内容排序到 webconf.csv 里,这个文件后面会用到。
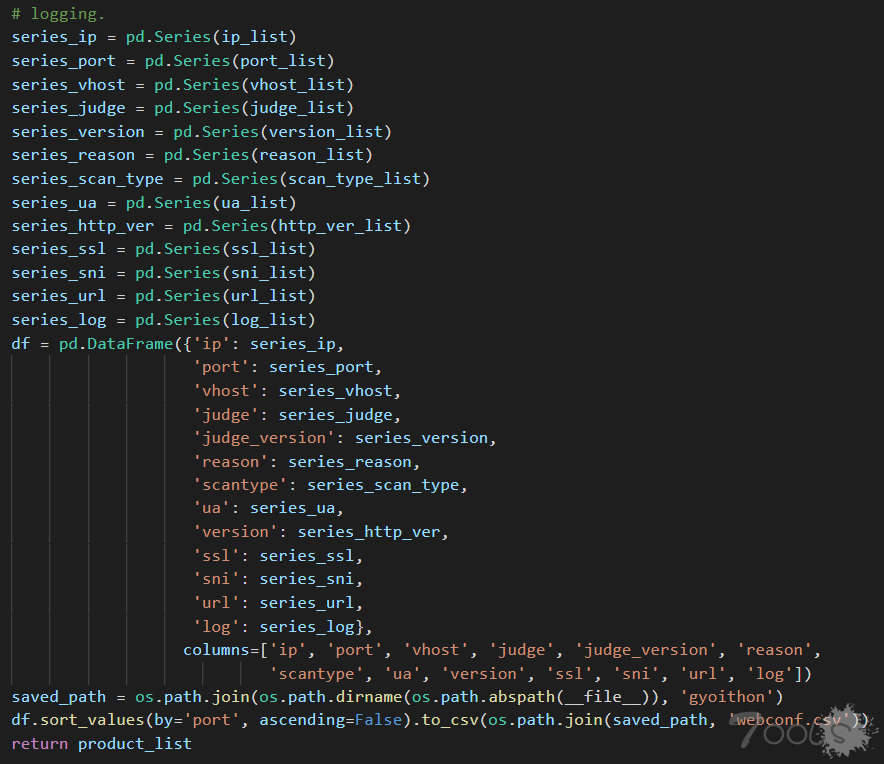
来看看 identify_product( ), 先 os.path.dirname(os.path.abspath(__file__)) 获取文件路径,然后拼接文件名字,再打开 /signatures/ 文件夹下的 signature ** .txt文件,按行读取至文件末尾后,赋值给 matching_patterns 。
进入循环,将 matching_patterns 里的值根据 ‘@’ 分割(为什么要根据@,下面会展示 signature ** .txt 的内容),取下标 [ 0 ] 的值,也就是 ‘@’ 左边的值给 product
取下标 [ 1 ] ,‘@’ 右边的值给 signature,然后调用 re.findall()这个正则表达式的模块来匹配,并忽略大小写,这个正则的函数会返回 response 中所有与 signature 相匹配的全部字符串,返回形式为数组。
最后输出一个结果(header),把 product、keyword_list 分别追加进 product_list、reason_list,return给调用者。
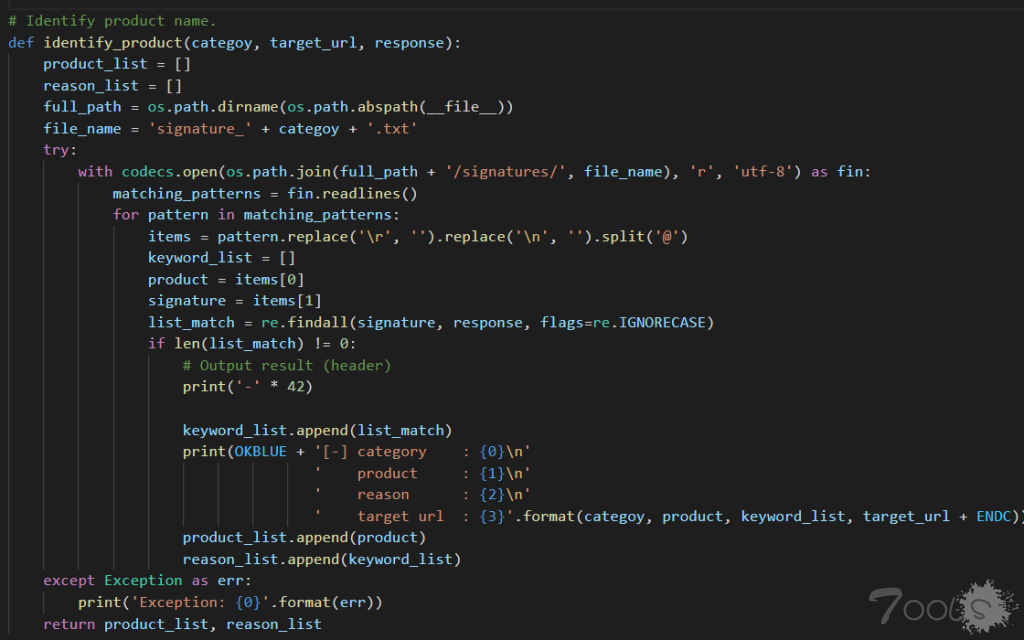
/signatures/ 文件夹如下:
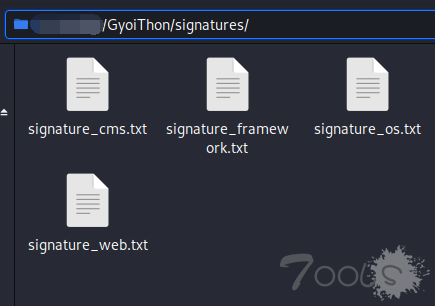
signature ** .txt 的部分内容,根据 ‘@’ 分割,左边是产品名称,右边是此产品的特征。读到这里如果再回看上面的 identify_product( ) 那里,可以更清晰的理解代码的目的。
回到 mian ,还有三个代码块,注释说明了它们各自的目的。
其中DeepClassifier()、Metasploit()、CreateReport()分别是调用了GyoiClassifier.py、GyoiExploit.py、CreateReport.py 这三个 .py 文件,关于这三个类的作用我在文章的开篇已经提到,这里就不再赘述。
这里可以看到 classifier 引用了 DeepClassifier 这个类,并且调用这个类里的 analyzer 函数。
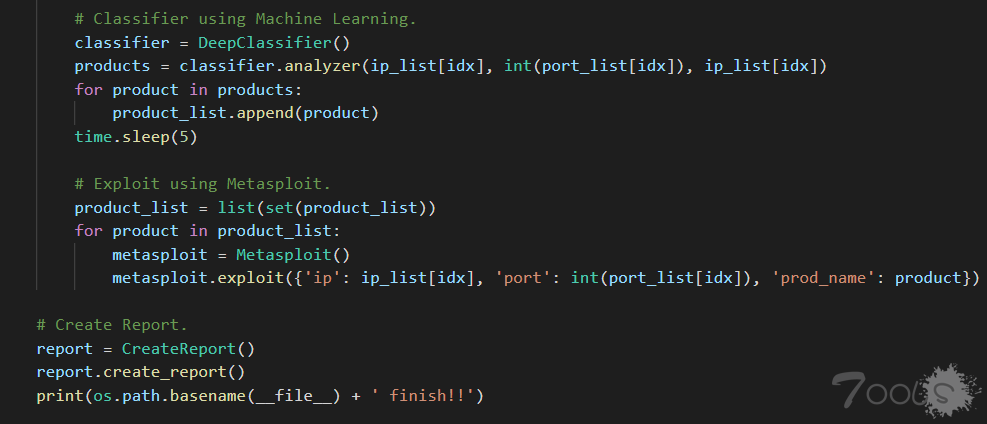
跟进 DeepClassifier(),直接跳到了 GyoiClassifier.py 。
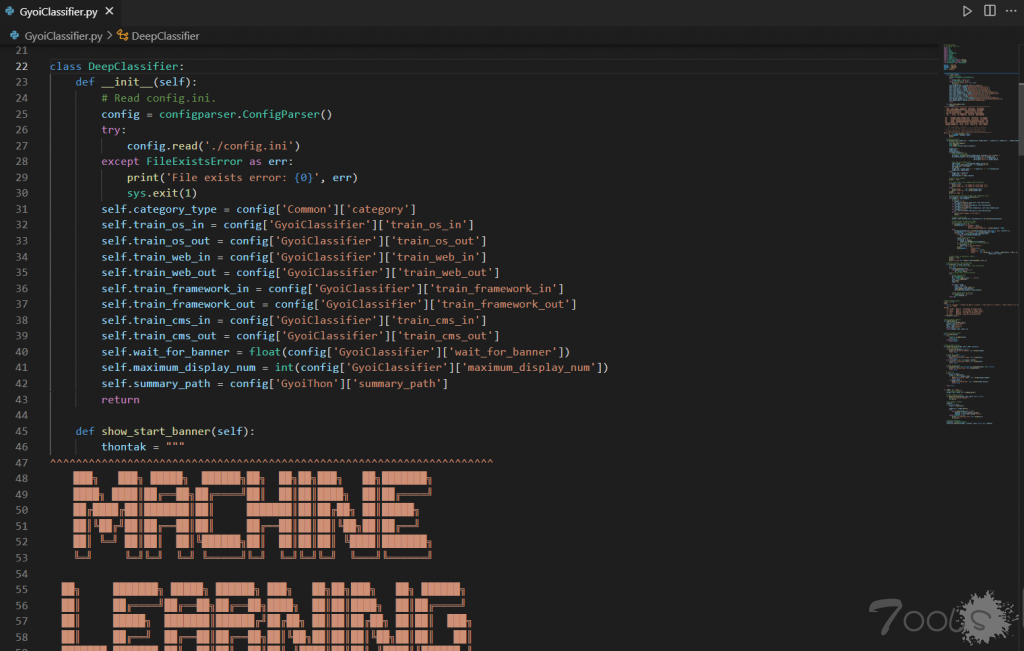
在 DeepClassifier 类里。首先是一个初始化函数 __init__( ),里面使用了 configparser 模块读取用户给定的 config.ini 配置文件,来拿到算法所需要的 “训练数据” 的文件的路径,并将这些路径赋值到定义的变量里,然后 return 跳出 __init__( ) 函数。
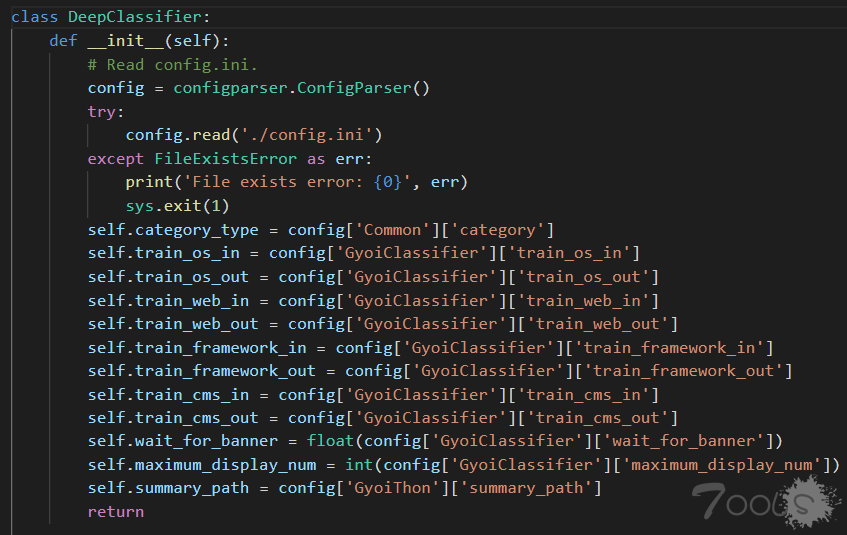
config.ini 配置文件如下:
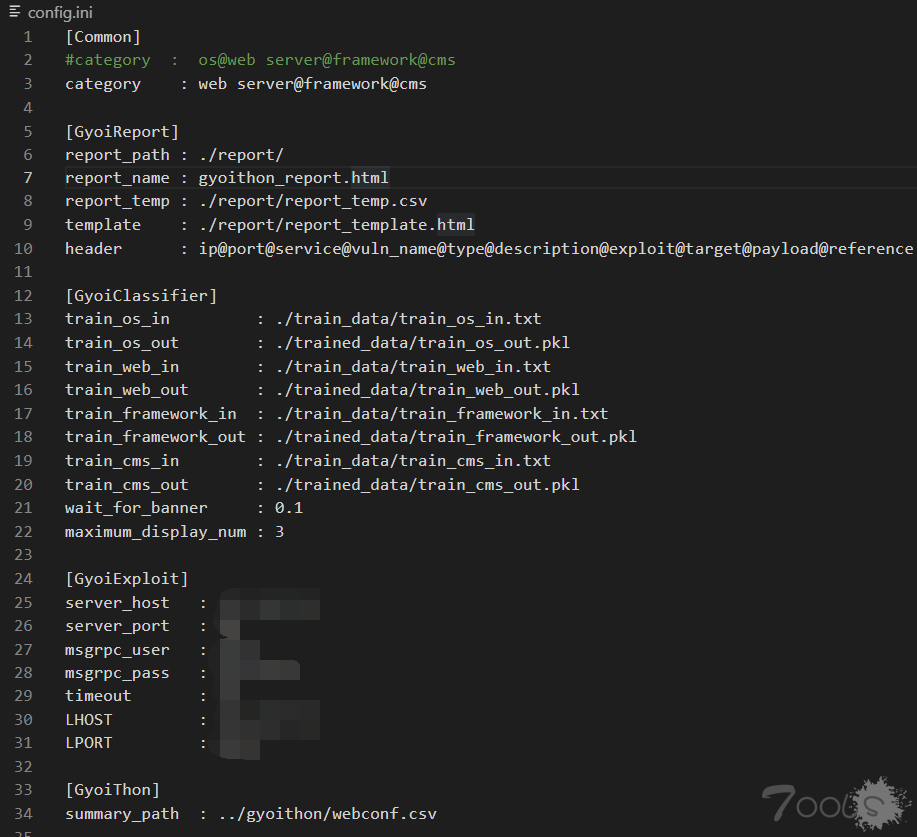
跟进 DeepClassifier 类的 analyzer()函数。它先是给用户提示字符,调用 show_start_banner()。
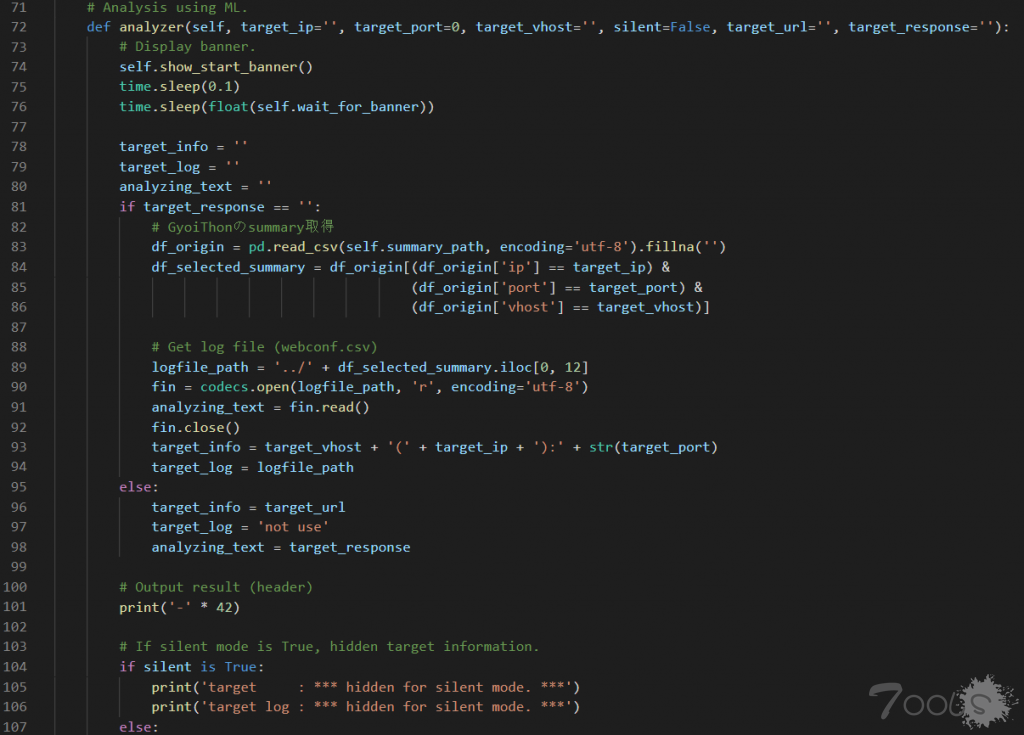
show_start_banner()如下:
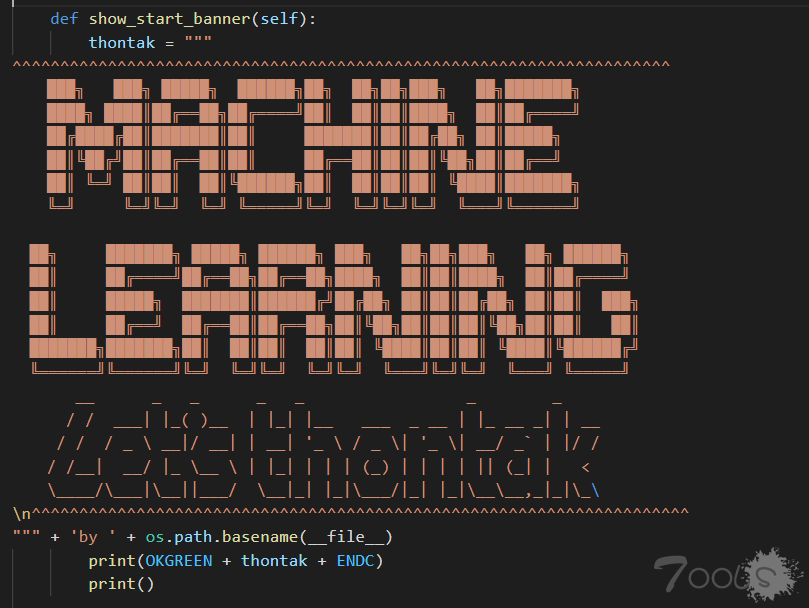
输出完字符后往下走,这里执行一个对刚才请求时获取到的目标 response 的判断,若其内容为空字符,则读取 webconf.csv 文件(webconf.csv文件在文章前面有提到),并将其内容赋值给 analyzing_text 。
若不为空,则直接将调用函数时传入的 response 参数的内容赋值给 analyzing_text 。
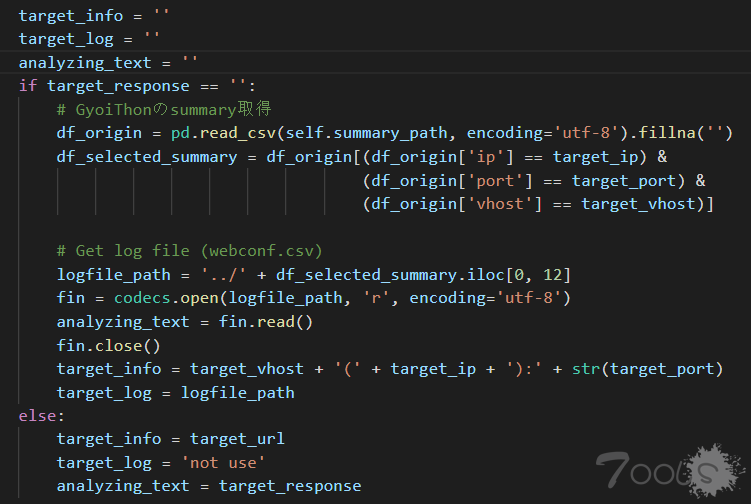
webconf.csv 的内容如下:
往下,这里判断是否为静默模式,若是,则隐藏目标信息,否则输出。
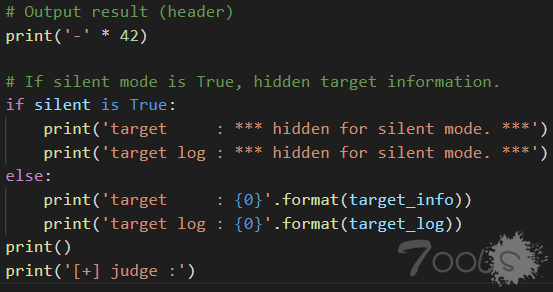
调用analyzer()时,如果不传参,静默模式默认是 False 。
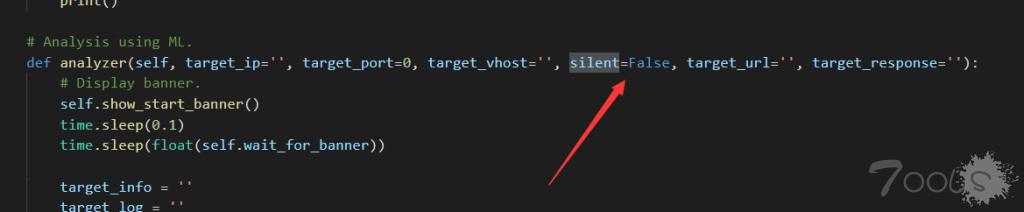
接着往下,这里将 config.ini 配置文件中的参数按照 '@' 分割拿到后,遍历里面的所有的值,然后根据对应的值去调用同一个函数 train(),并依次传入不同的参数。
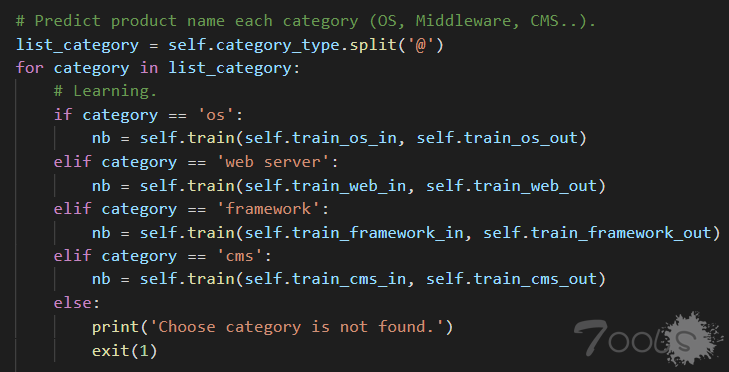
跟进 train(),这里的 in_file 参数里的值是 train_***_in.txt、out_file 是 train_***_out.pkl,分别代表学习前的数据,和学习过的数据。
里面执行一个对 out_file 的判断,若已存在学习过的数据,就意味着本地已经有了对此种目标类型学习训练过后而产出的指纹数据,则直接读取此 .pkl 文件里经过“朴素贝叶斯”算法,进行特征分类过后得到的指纹,赋值给 nb 并将其 return 给调用者 。
若不存在,说明此次目标是未知的新种类目标,则先引用 NaiveBayes 类,然后打开并按行读取未学习过的 in_file 文件,再把此次学习了的数据写入 out_file ,最后赋值给 nb 并将其 return 给调用者 。
跟进 NaiveBayes()就跳到了 NaiveBayes.py,这里就是“朴素贝叶斯”机器学习算法的代码实现,也是此款工具最有新意的地方。
它的逻辑复杂度很高,但我们是做安全的,而不是搞Ai算法的,所以没必要深究,只需要了解其大概原理,并能将其应用就足够了。
我对其的理解,简单总结就是;朴素贝叶斯算法,应用在攻防里的指纹识别中:朴素贝叶斯会假定数据是互相具有独立特征的,并在学习过程中将其根据特征分类。
在学习中,逐步提高准确分类特征的概率。
将要识别的目标根据特征分类,以提高后续在根据特征来判断产品的模块时的准确率,变相的提高程序在后续根据产品来执行的攻击时的准确率。
关于“朴素贝叶斯”的原理,网上很多,大家自行查阅,这里就不赘述了。
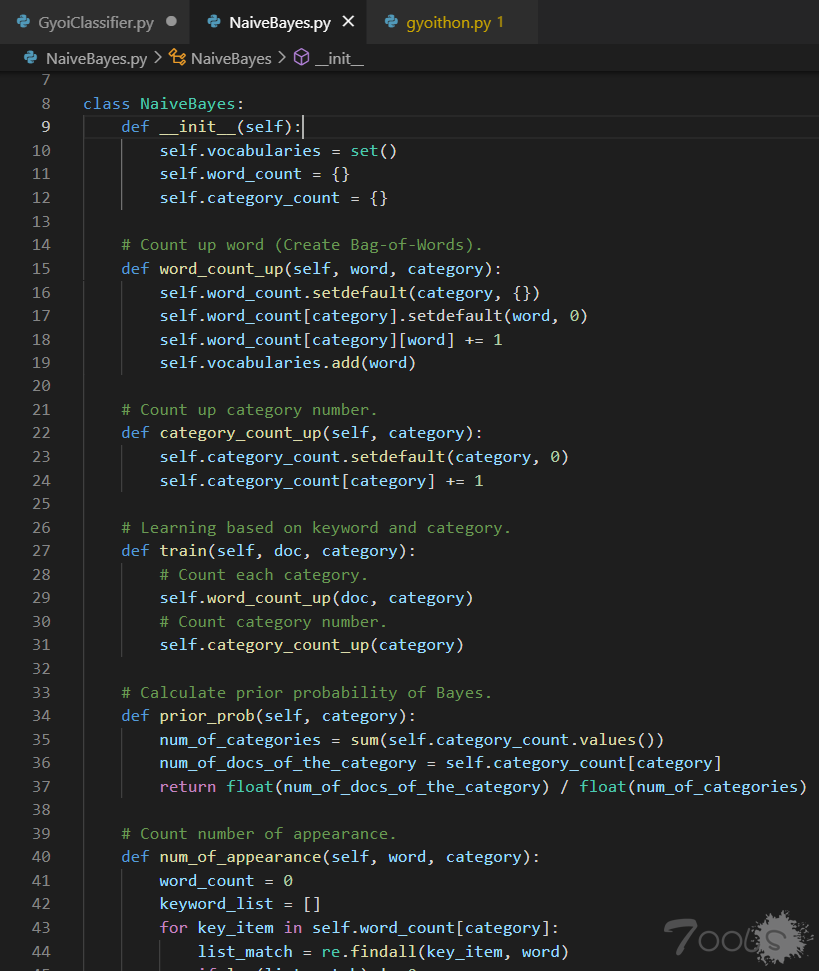
回到GyoiClassifier.py。执行完 train() 后,继续往下走。
这里调用了 NaiveBayes 算法实现类里的 classify()来计算数据的内容并分类。参数 analyzing_text 是之前传入的 response 内容,这个上面有提到过。

往下。大家看输出的内容就可得知,这里就是对算法给出的结果做了一系列的判断与输出。
程序走到这里,被 classifier 调用的 analyzer()函数也执行完毕了。
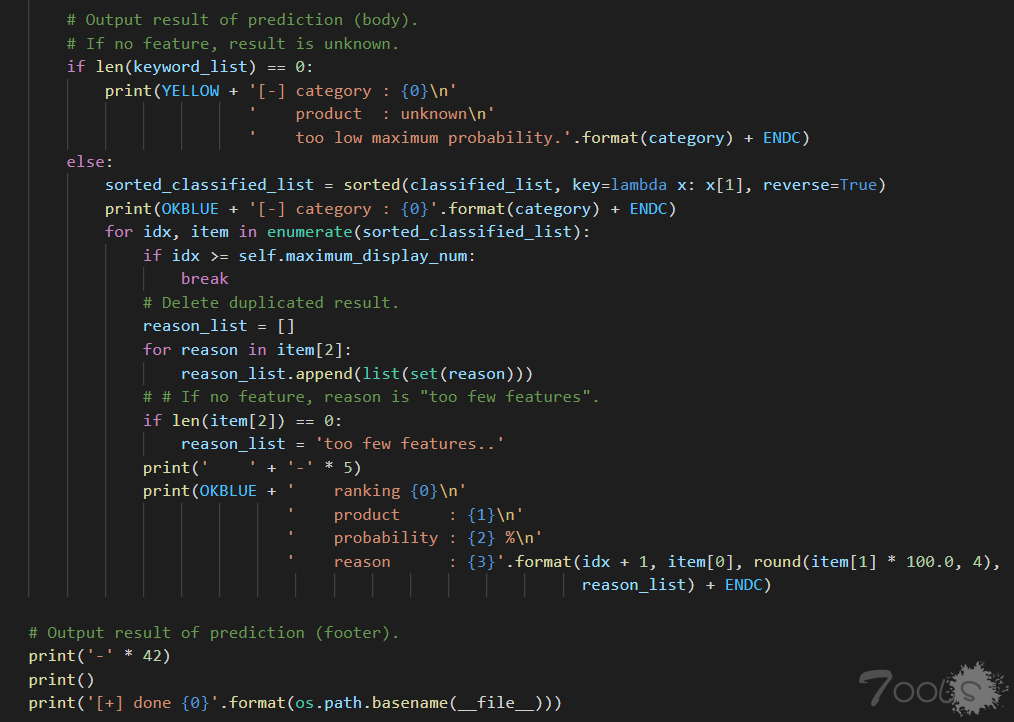
analyzer()调用结束,线程回到 gyoithon.py 的 mian 这里。拿到 products 后,将其循环追加进 product_list 中,最后让线程睡眠5秒之后,执行下一个代码块。
其中 product_list 是作为程序执行下一个 Metasploit 攻击模块时的参数。
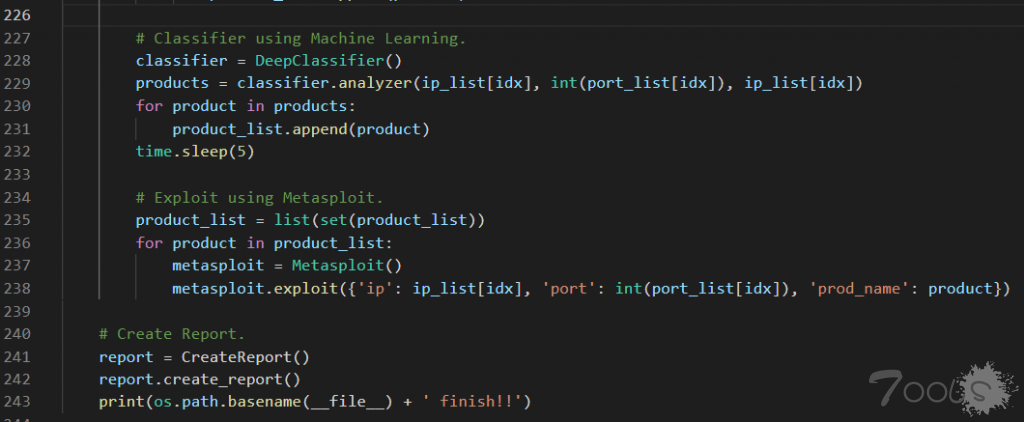
文章前面有提到,这三个代码块从上往下,依次会执行 GyoiClassifier.py、GyoiExploit.py、CreateReport.py,这三个文件的作用依次是 “机器学习算法的特征分类”、“调用 metasploit 执行攻击”、“生成渗透测试报告”。
而此款工具我认为最有新意,和核心的地方是在执行了 NaiveBayes.py 朴素贝叶斯算法的 GyoiClassifier.py ,这里是Ai 结合渗透的具体实现 。
至于 GyoiExploit.py、CreateReport.py,在我阅读过里面的代码后,得知分别就是调用了 metasploit 来做攻击,和使用浏览器来生成一份渗透测试报告,没太多创新的地方,不是我此篇文章想写的内容,就先不做过多的介绍了。
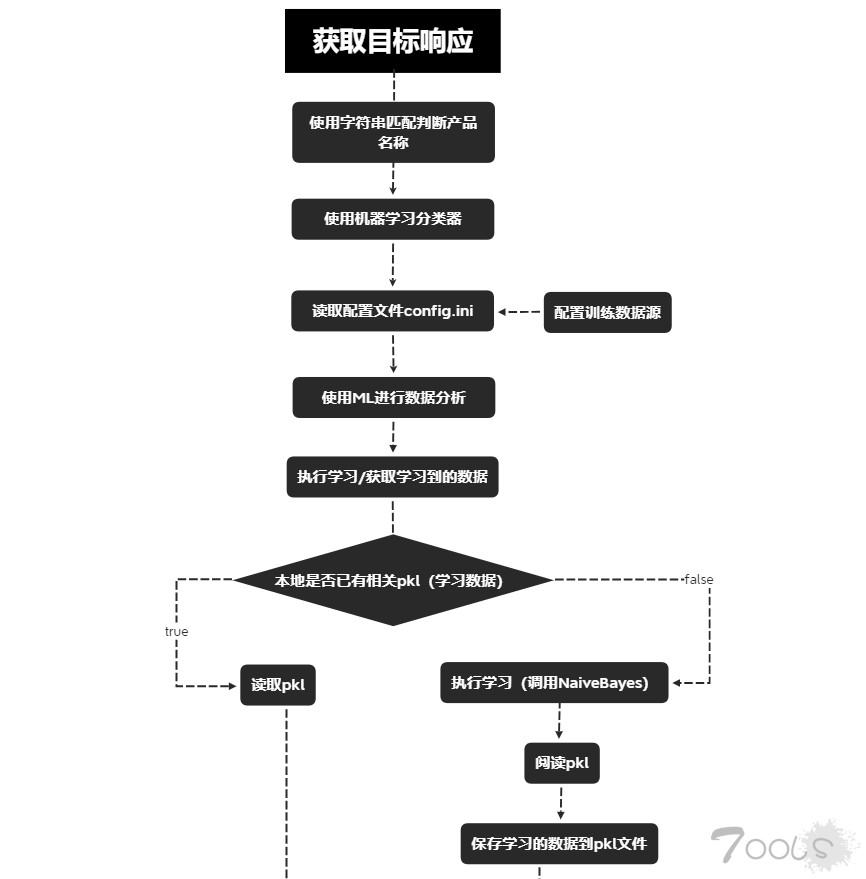
经过核心源码分析,我们可以画出这样一份大概的流程图:
总的来说,gyoithon 结构还是很简单的,难的是 “朴素贝叶斯” 背后的代码实现,不过前人的积累已经很成熟了,我们将其熟练应用就好了哈哈...
此篇文章到这里就暂时结束了,感谢阅读。
有不对或者疏忽的地方,请一定要指出,谢谢
自评TCV 2
评论5次
机器学xi很烧脑,如果只是单纯的调用一些py里面的机器学xi的模块调参的话还是不算太难的,py最有优势的地方就是ai这一块了
还能这样玩,厉害了
有先见之明
使用机器学xi及这中高端的算法,对实际场景中作用的提升到底有多大?一直都很好奇